Seizing the Means of Transclusion
Even before popularizing Self-Contained Systems, INNOQ and friends have been championing transclusion as a simple and effective integration mechanism between web applications: Embedding HTML snippets generated by another system means we can delegate responsibility for content without relying on complex API contracts.1 (We did not, of course, invent transclusion.)
We’ve since become a little more wary of this technique, as we’ve seen it being used excessively and turn into a footgun, not least when it comes to front-end components and their dependencies. Nevertheless, when used wisely – which often means imposing strict limits on what qualifies as transcludable markup (in other words, establishing an explicit contract) – it can be a very powerful tool.
Enterprise-Scale Blogging
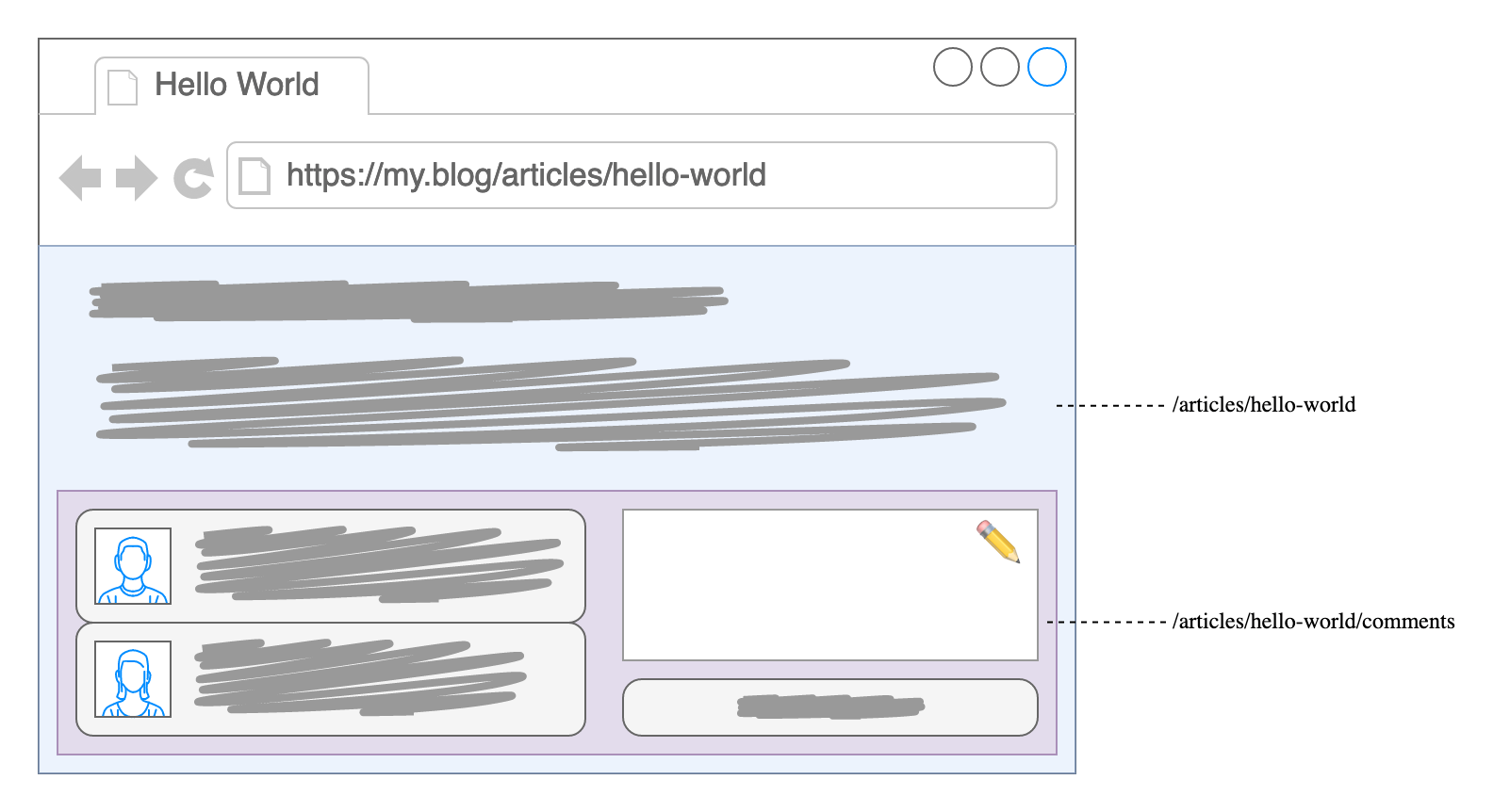
Perhaps your blog allows people to leave comments. You might decide to split articles and comments into separate resources (as in URLs) in order to optimize caching as comments tend to be more volatile. Those resources might even be provided by two independent applications, to account for different requirements (think authentication, moderation etc.) or varying request load. With responsibilities divided that way, you could rope in a friend to manage comments for your clique’s web ring while you focus exclusively on serving static files generated from Markdown.
If you’re more the commercial type, imagine a product page with recommendations for similar items – or perhaps a shopping cart accompanying you across multiple pages. Administrative folks might picture their inbox being augmented by a calendar on the side, delighted by an unread counter haunting their documents’ navigation bar. That bar at the top might also include their user profile – all drawn from dedicated resources.
Rehabilitation
We’ve split our system into separate parts, for purely technical reasons. Now we need to recombine those distinct resources into a single page, seamlessly if possible: End users shouldn’t have to care about about our internal system boundaries.
Transclusion makes this possible without complex orchestration: Primary content – our article – contains placeholders where secondary content – vistors’ comments – should appear.2 Any such placeholder points to the respective URL, which is then resolved – or “dereferenced”; replacing the placeholder with the corresponding content. In our case that’s HTML representing comments, if any, and conceivably including an HTML form to submit a new comment.
Implementation Options
Of course that leaves the question: Who is gonna do the dereferencing, retrieving secondary content and swapping out the placeholder? Given we’re in a client-server environment, there are a few options: The client, the application server (AKA “origin server”) or an intermediary, i.e. some sort of proxy server.

Our blog system (articles beneath) could integrate comments directly:
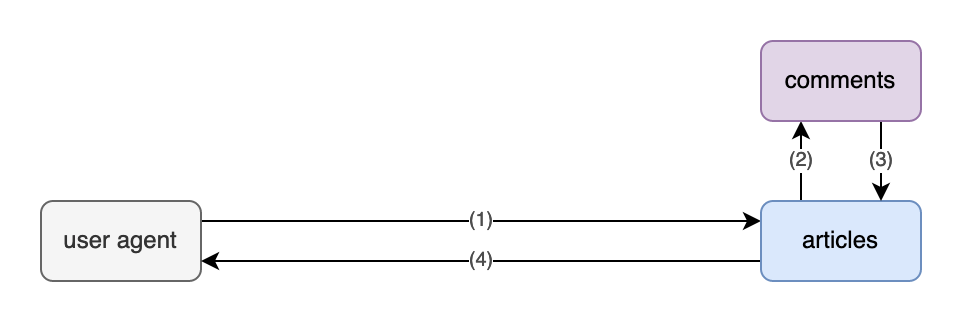
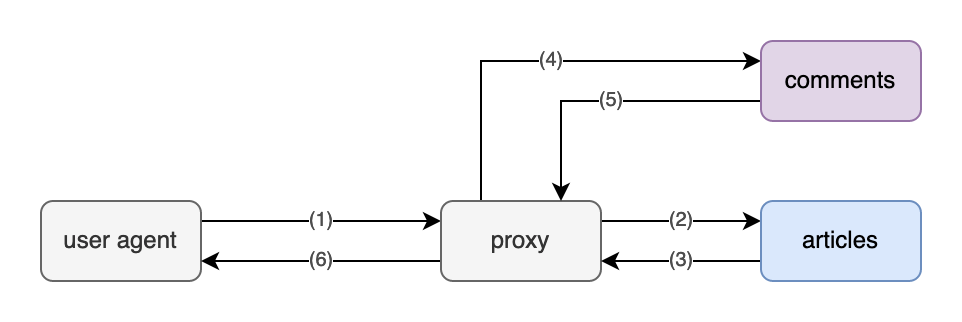
Alternatively, we might delegate that task to a proxy under our control:
Or we just leave it to clients:
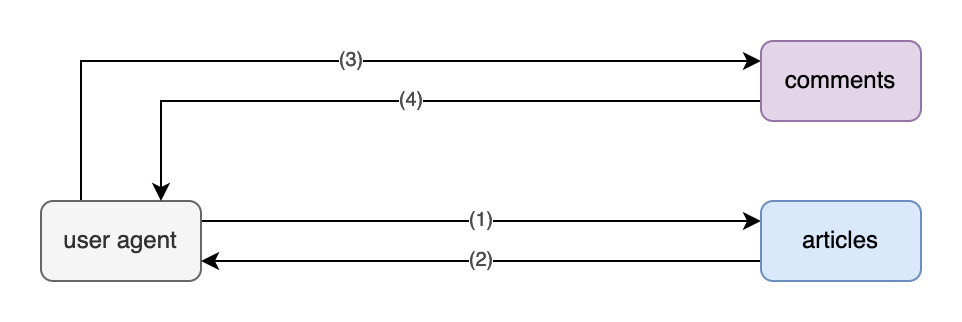
Arguably, the most straightforward way for an application to indicate placeholders would be to generate a regular old link and leave transclusion to some other part of the chain:
<h1>Hello World</h1>
<p>…</p>
<a class="is-transcludable" href="/articles/hello-world/comments">comments</a>Client-Side
Assuming we’re targeting web browsers, a bit of JavaScript (e.g. h-include or embeddable-content, possibly even just iframes) could then hook into that, retrieve the corresponding content and replace the link. Error handling is pretty straightforward: If transclusion fails (e.g. due to network issues, including timeouts, or because JavaScript is unavailable), we can just leave the link right there. Typically that’s still better user experience than failing outright; transcluding secondary content can be thought of as a progressive enhancement. Of course we could implement more elaborate error handling if warranted, perhaps explaining why the respective content is currently unavailable.
However, relegating transclusion to the client might have undesirable consequences: Secondary content might flicker into existence, FOUC-style, as the link is rendered first and replaced afterwards. Also, making every single client request both resources might be inefficient and increase server load: If secondary content is publicly cacheable (which, among other things, excludes personalized content and anything requiring authentication), moving transclusion to the server side potentially reduces the number of requests quite significantly.3
Server-Side
For that we could use Server Side Includes (SSI) within a proxy server, such as Apache or nginx. Unfortunately we can’t use a regular link there, as SSI – for lack of a common standard – prescribes its own syntax:
<!--# include virtual="/articles/hello-world/comments" -->SSI is widely supported, but it comes with significant flaws – most notably severely limited error handling4. Debugging can also be very painful. Edge Side Includes (ESI) are similar and address some of those flaws, though support is a little more spotty: While SSI can often be enabled on an existing reverse proxy, ESI typically needs a separate installation.
Many CDNs have more powerful scripting facilities for manipulating outgoing HTML, allowing for pretty much the same flexibility as with client-side JavaScript. Some even support streaming HTML, which can provide a huge performance boost.
Various companies and individuals have rolled their own solutions, with sometimes frightening complexity. The rationale there is sometimes to avoid slowing things down: We don’t want primary content to be blocked while retrieving secondary content. (That’s something we get for free with the client-side approach.)
Lastly, while implementing transclusion within our application might appear simple at first, it often turns out to be tricky: Correctly managing HTTP requests and caching is not trivial. It also puts additional strain on the origin server.
Conclusion
We should be very conscious of when and how we employ transclusion. As with all distributed systems, adequate error handling should be built in from the start. Server-side transclusion can be thought of as an optimization, which works best with highly cacheable content, at the cost of increased infrastructure complexity. It might be perfectly sensible to use both client-side and server-side transclusion within the same application, depending on the use cases.